题目
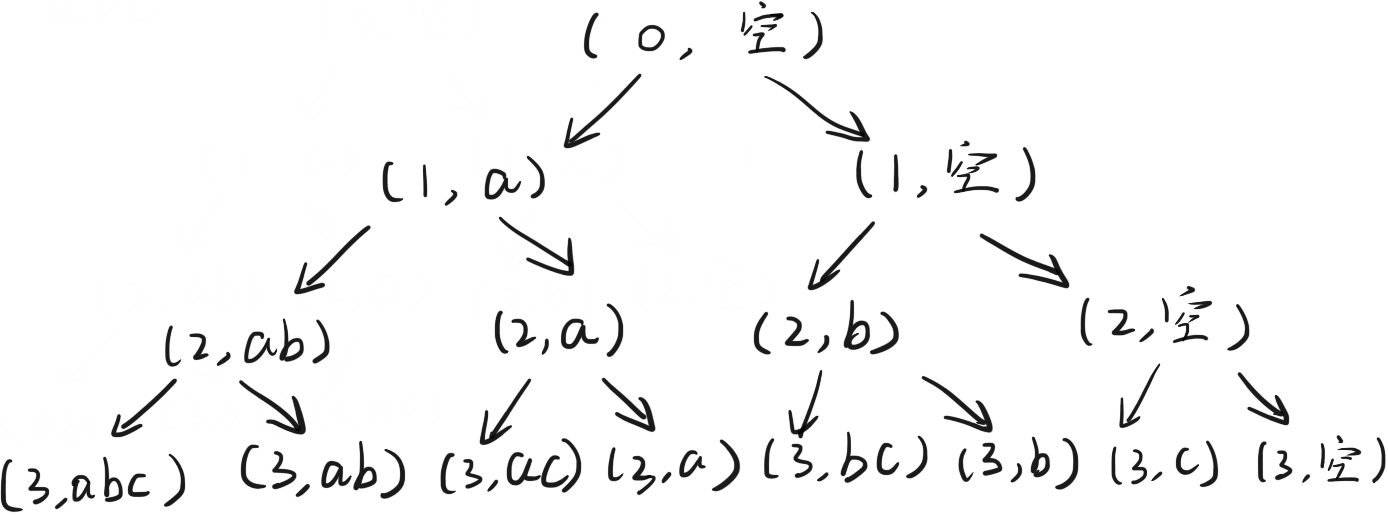
打印一个字符串的全部子序列, 包括空字符串
题解
迭代过程中, 要么当前字符保留, 要么略过
Java
1 | public class Subsequence { |
1 | abc |
Python
1 | def print_subsequence(string): |
打印一个字符串的全部子序列, 包括空字符串
迭代过程中, 要么当前字符保留, 要么略过
1 | public class Subsequence { |
1 | abc |
1 | def print_subsequence(string): |
打印 n 层汉诺塔从最左边移动到最右边的全部过程
假定三根柱子分别为 from , to 和 help , 该问题可划分为 3 个步骤
1~(n-1) 从 from 移动到 help 上n 从 from 移动到 to 上1~(n-1) 从 help 移动到 to 上其中, 将 1~(n-1) 从 help 移动到 to 的过程又可分为多个子问题, 需不断调整三个柱子的角色.
1 | public class Hannoi { |
1 | def hannoi(n, source, target, assist): |
给定两个数组 w 和 v ,两个数组长度相等,w[i] 表示第i件商品的 重量,v[i] 表示第i件商品的价值。 再给定一个整数 bag ,要求你挑选商品的重量加起来一定不能超过 bag ,返回满足这个条件下,你能获得的最大价值。
解法类似上一篇博客
穷举所有可能的结果, 迭代过程中判断累计重量 acc_weight 是否超过 bag , 若超过则返回 Integer.MIN_VALUE , 相当于直接舍弃该分支. 另一个迭代的基础条件为当 i 达到 w.length 时, 返回 0 , 因为第 i 次递归的返回值为当前商品的价值 v[i] 加上后续商品的价值与只有后续商品价值二者中的较大者, i 等于 w.length 时, 没有后续商品, 故直接返回 0 .
1 | public class Knapsack { |
1 | def max_value(w, v, i, acc_weight, bag): |
此类无后效性的递归问题均可转化为动态递归.
1 | public class Knapsack { |
1 | def max_value(w, v, bag): |
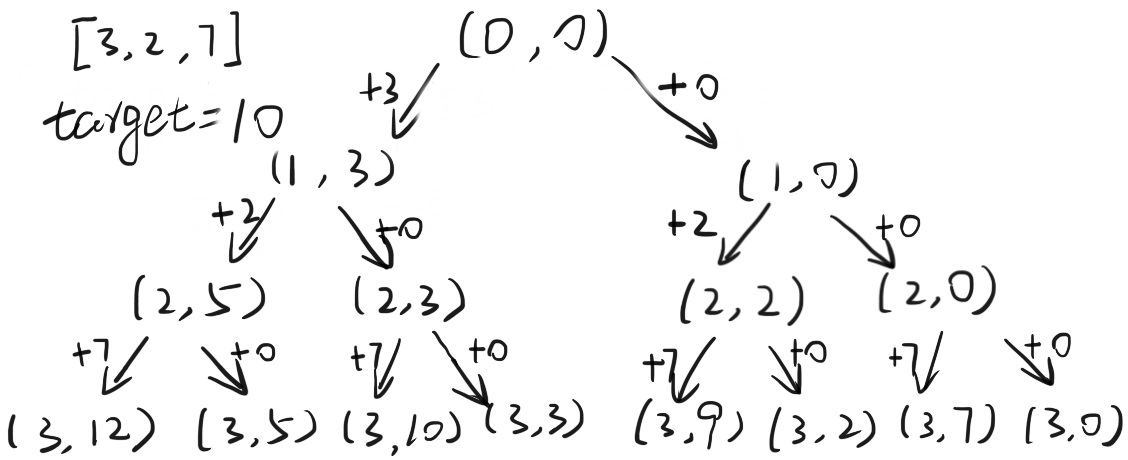
给定一个正整数数组 arr 和一个整数 target , 如果可以任意选择 arr 中的数字, 求能否累加得到 target .
穷举所有可能的和, 判断是否含有 target , 穷举过程如下, 其中中间变量格式为 (i, sum) , i 为索引, sum 为当前的累加和, 左支表示累加 arr[i] , 右支表示跳过该值.
1 | public class SumToTarget { |
1 | def sum_to_target(arr, i, cur_sum, target): |
将暴力递归改进为动态规划时, 无需考虑原题目的含义, 只需找到迭代时各变量之间的依赖关系即可. 递归到动态规划的转化方法:
n 个参数, 就定义一个 n 维的数组1 | return isSum(arr, i + 1, sum + arr[i], target) || isSum(arr, i + 1, sum, target); |
由上述代码知递归函数第 i 次递归的结果只依赖于 i+1 和 sum , 故需定义一个 i+1 和 sum 状态关系的数组. 递归函数参数 i 的取值范围为 0~arr.length , sum 的范围为全部元素都不取到全部元素的和, 以 [3, 2, 7] 为例即为 0~12 . 构成的数组如下:
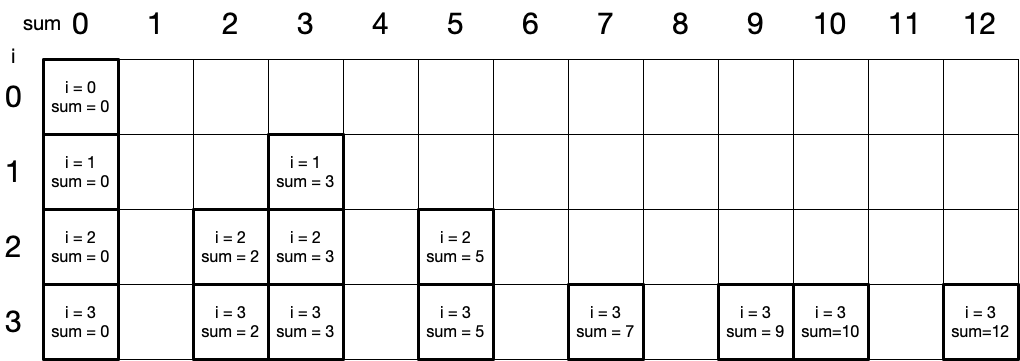
任意一格 (i, sum) 的值仅由 (i+1, sum) 和 (i+1, sum+arr[i]) 决定. 如上表所示, (1, 3) 的值取决于 (1+1, 3) 和 (1+1, 3+arr[1]) , 其中 arr[1] 为 2, 故 (1, 3) 的真值取决于 (2, 3) 和 (2, 5) 的真值.
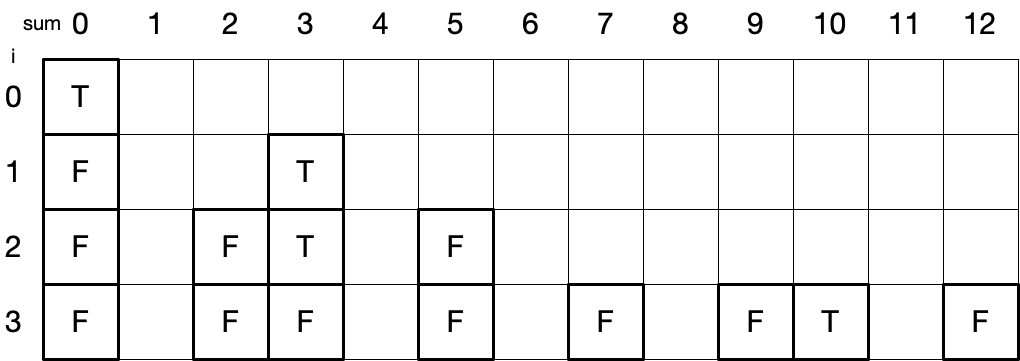
最终结果返回表中 (0, 0) 位置即可.
1 | public class SumToTarget { |
1 | def sum_to_target(arr, target): |
给定一个包含非负整数的 m x n 网格,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
说明: 每次只能向下或者向右移动一步。
示例:
输入:
1 | [ |
输出: 7
从左上角到右下角, 每次移动只有向右或向下两种可能, 需递归地找出左右两个方向到右下角路径和较小者即可.
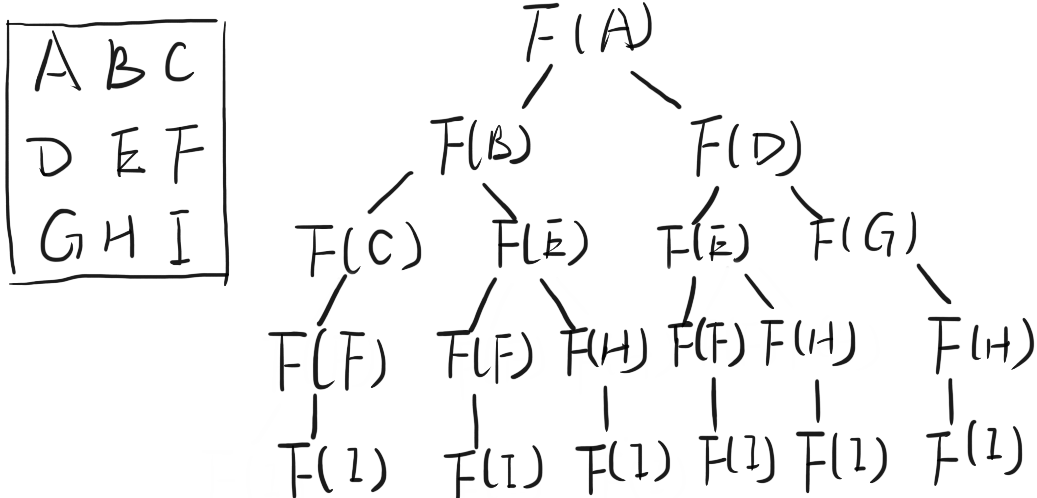
暴力递归不记录子状态的结果, F(E) , F(H), F(F) 进行了多次重复计算, 占用较多空间, 数据较多时会超时, 可改用计划搜索的方法进行优化.
1 | public class MinimalPathSum { |
1 | def get_minimal_path_sum(grid): |
将每个子状态的运算结果存入缓存中, 若之前计算过则直接返回计算结果.
1 | public class MinimalPathSum { |
1 | class MinimalPathSum: |
左上角到右下角的最短距离与右下角到左上角最短距离相同, 为便于表示, 以下改为求右下角到左上角的最短距离.
由以上计划搜索部分知, 当矩阵中某点的位置即 i 和 j 的值确定时, 该点到左上角的最短路径就确定了, 故可单独求出矩阵中各元素到左上角的最短路径, 每个元素的最短路径值仅由其相邻的左边和上边元素决定, 其对应关系如下例, 故输出矩阵中的右下角即为左上角到右下角的最短距离.
输入
1 | 3 8 6 0 5 9 9 6 3 4 0 5 7 3 9 3 |
输出
1 | 3 11 17 17 22 31 40 46 49 53 53 58 65 68 77 80 |
1 | public class MinimalPathSum { |
1 | class MinimalPathSum: |
最小生成树是一副连通加权无向图中一棵权值最小的生成树。一个连通图可能有多个生成树。当图中的边具有权值时,总会有一个生成树的边的权值之和小于或者等于其它生成树的边的权值之和 (Wikipedia)。
常见算法有 Kruskal 算法和 Prim 算法
按照边的权重顺序(从小到大)将边加入生成树中,但是若加入该边会与生成树形成环则不加入该边。直到树中含有顶点数减一条边为止。这些边组成的就是该图的最小生成树。
实现过程中, 可利用小根堆来依次返回权重最小的边, 利用并查集来避免生成树形成回路.
UnionFind 定义如下
1 | class UnionFind { |
Kruskal 实现
1 | public class KruskalMST { |
UnionFindSet 定义见并查集
由于 Edge 对象不能够直接比较大小, 需重写 Edge 的比较函数, __lt__ 对应 < , __gt__ 对应 > , 只重写其中一个, 另一个会自动取反. 比较相等时结果相同.
1 | class Edge: |
Kruskal 实现
1 | from heapq import * |
从任意一个节点开始, 将与其相连的几条边全部放入一个小根堆中, 每次弹出小根堆中权重最小的边, 获取该边的另一端节点放入集合中, 并将另一端节点的所有直接相连的边放入小根堆中, 迭代直到小根堆中的边全部取出为止.
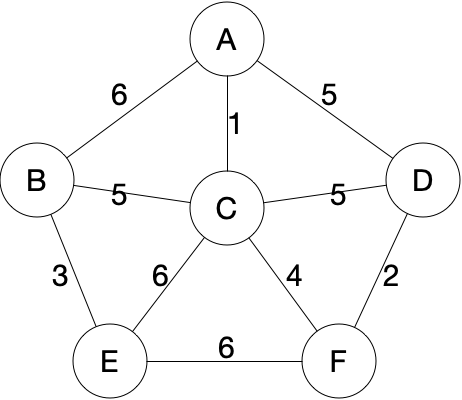
1 | public class PrimMST { |
1 | 1 3 2 4 5 |
1 | def prim_mst(graph): |
在图论中,由一个有向无环图的顶点组成的序列,当且仅当满足下列条件时,才能称为该图的一个拓扑排序(Topological sorting):
适用范围:
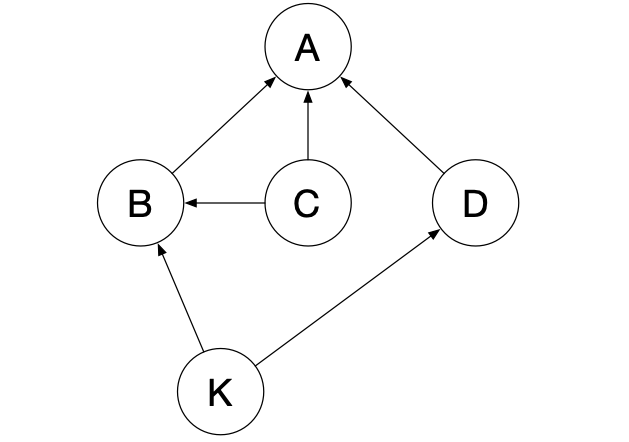
拓扑排序常应用于有依赖关系的一组事务之间的排序. 例如有依赖关系的多个模块的编译次序问题等. 假定下图中的 A , B , C , D , K 为待编译的几个模块, 箭头表示依赖关系(如 B , D 依赖于 K ), 经拓扑排序后应输出模块编译顺序, 即 K -> C -> B -> D -> A 或 C -> K -> B -> D -> A ( K 和 C , B 和 D 顺序可互换)
先找到所有入度为 0 的节点并输出, 删除这些节点. 在下一次迭代中, 找到剩余节点中入度为 0 的节点并输出, 直到图中节点全部输出为止.
图的结构定义及实现见另一篇博客
1 | public class TopologySort { |
1 | def topology_sort(graph): |
借助栈和集合实现树和图的深度优先遍历, 每次从栈中取出一个节点 A , 遍历与节点 A 相邻的后续节点 Bn , 若集合中没有该后续 Bn 则将节点 A 放回栈中, 并将后续节点 Bn 放入栈和集合中, 输出后续节点 Bn . 每遍历完一个后续节点就跳出当前循环, 避免出现横向遍历 ( 如下图, 可能会产生 2, 3, 4 的错误输出 ).
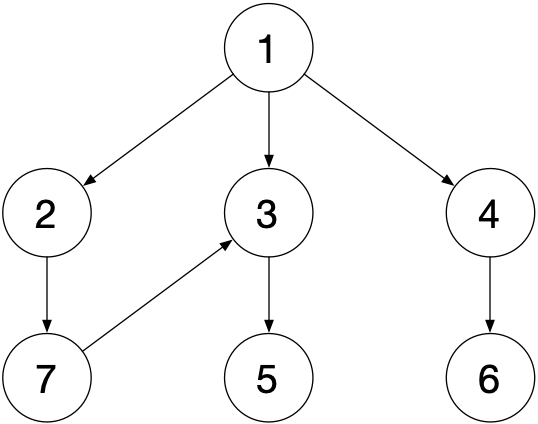
以上图为例, 图的节点定义及整体结构见上一篇博客
1 | public class DFS { |
1 | 1 2 3 5 7 4 6 |
1 | def dfs(node): |
树和图的广度优先遍历可借助一个队列和一个集合实现. 先将当前节点分别放入队列和集合中, 再依次出队, 出队元素将其下一个节点进队, 迭代即可实现广度优先遍历.
以上图为例, 图的节点定义及整体结构见上一篇博客
1 | public class BFS { |
1 | 1 2 3 4 7 5 6 |
1 | from queue import Queue |
实际开发中常用二维矩阵表示图, 矩阵中的每一行即为一条边, 格式如 [权重, 起始点, 结束点]
1 | [ |
以上矩阵所表示的结构如下:
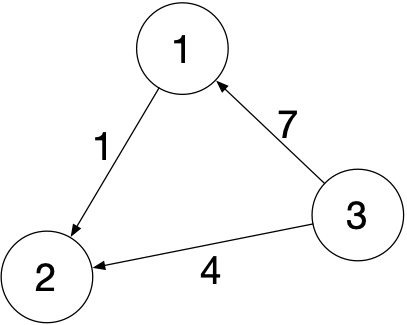
1 | class GraphNode { |
1 | class GraphNode: |