classTreeNode { int val; TreeNode left; TreeNode right;
publicTreeNode(int val) { this.val = val; } }
publicclassPreorderTraversal { public List<Integer> preorderTraversal(TreeNode root) { List<Integer> result = newArrayList<>();
if (root != null) { Stack<TreeNode> stack = newStack<>(); stack.push(root);
TreeNode tmp; while (!stack.isEmpty()) { tmp = stack.pop(); result.add(tmp.val);
if (tmp.right != null) { stack.push(tmp.right); }
if (tmp.left != null) { stack.push(tmp.left); } } }
return result; } }
Python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classPreorderTraversal: defpreorder_traversal(self, root): result = [] if root: stack = [] stack.append(root) while stack: tmp = stack.pop() result.append(tmp.val) if tmp.right: stack.append(tmp.right) if tmp.left: stack.append(tmp.left) return result
classPostorderTraversal: defpostorder_traversal(self, root): result = [] if root: stack = [] help_stack = [] stack.append(root) while stack: tmp = stack.pop() help_stack.append(tmp.val) if tmp.left: stack.append(tmp.left) if tmp.right: stack.append(tmp.right) while help_stack: result.append(help_stack.pop()) return result
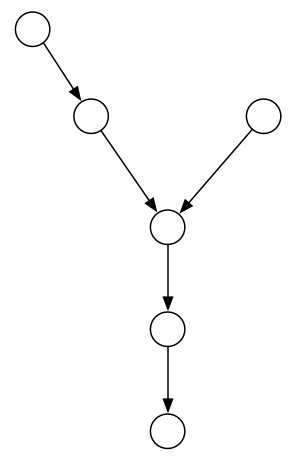
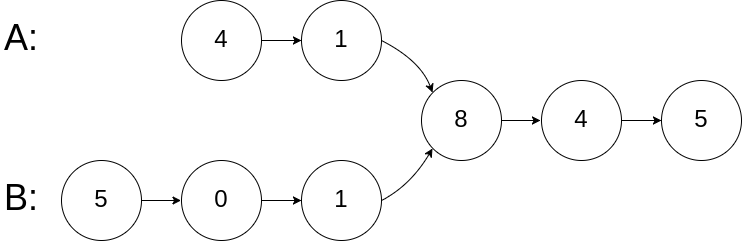
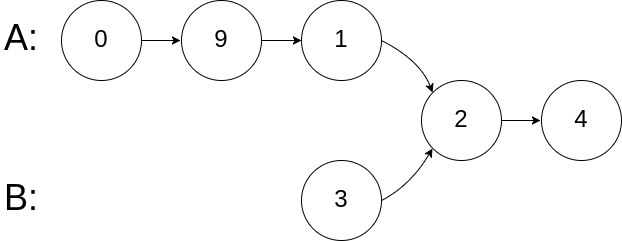
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3 输出:Reference of the node with value = 8 输入解释:相交节点的值为 8 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 2:
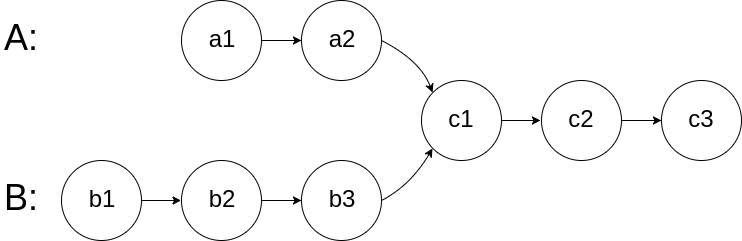
1 2 3
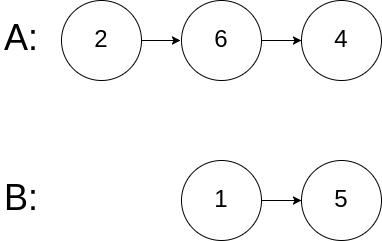
输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1 输出:Reference of the node with value = 2 输入解释:相交节点的值为 2 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。