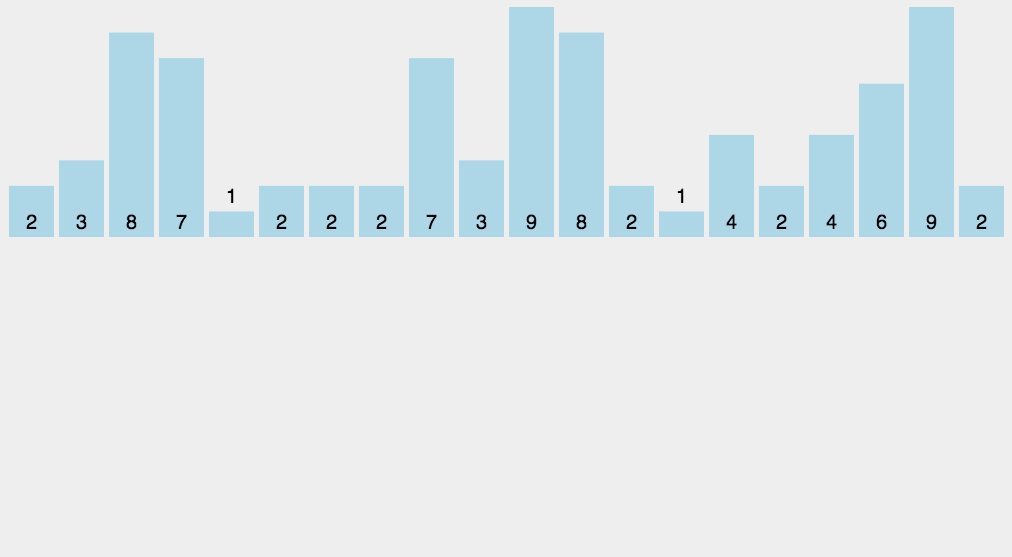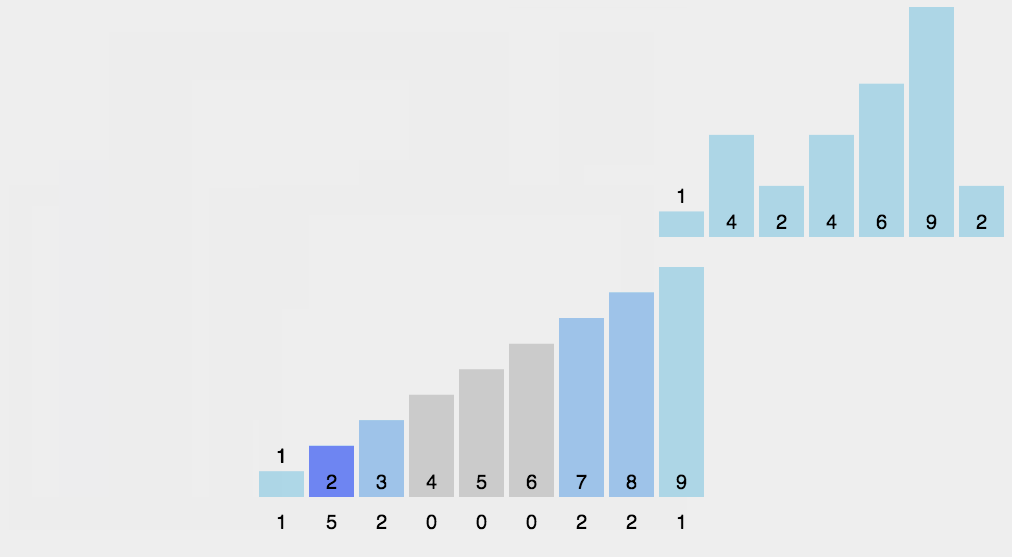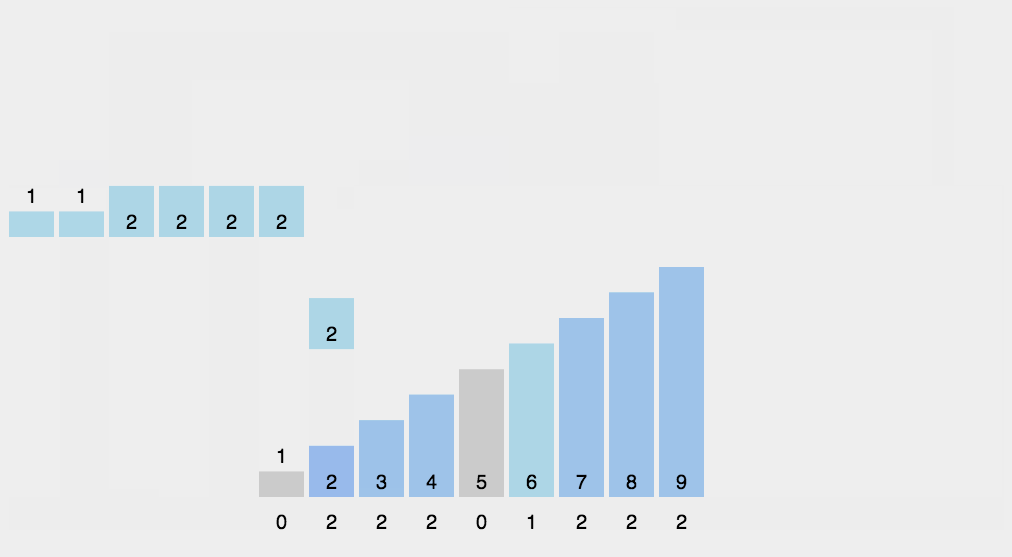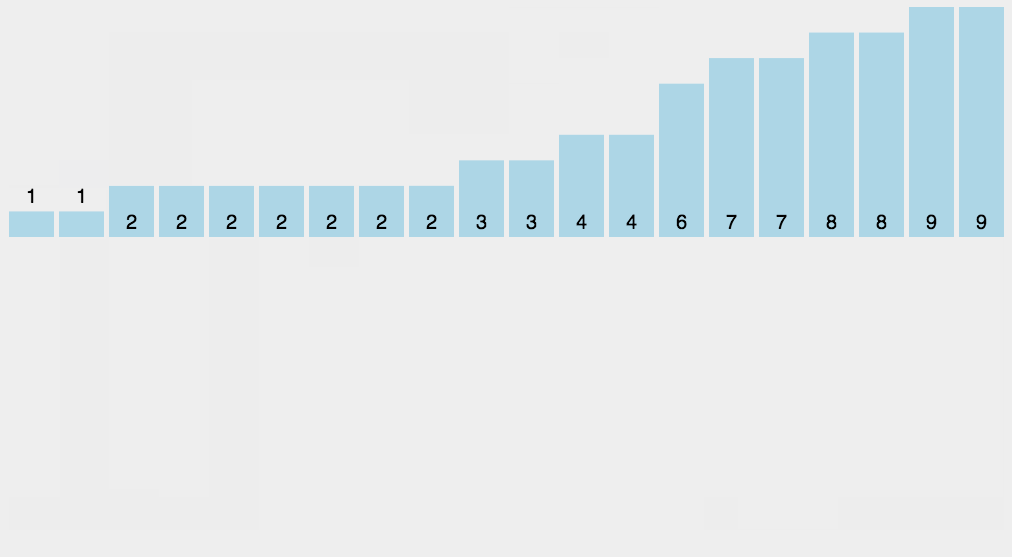/** * Initialize your data structure here. Set the size of the queue to be k. */ publicMyCircularQueue(int k) { arr = newint[k]; size = 0; start = 0; end = -1; }
/** * Insert an element into the circular queue. Return true if the operation is * successful. */ publicbooleanenQueue(int value) { if (size == arr.length) { returnfalse; } size++; end = nextIndex(end); arr[end] = value;
returntrue; }
/** * Delete an element from the circular queue. Return true if the operation is * successful. */ publicbooleandeQueue() { if (size == 0) { returnfalse; } System.out.println("deQueue: " + arr[start]); size--; start = nextIndex(start);
returntrue; }
/** * Get the next index. */ publicintnextIndex(int index) { return index == arr.length - 1 ? 0 : index + 1; }
/** * Get the front item from the queue. */ publicintFront() { if (size == 0) { return -1; } return arr[start]; }
/** * Get the last item from the queue. */ publicintRear() { if (size == 0) { return -1; } return arr[end]; }
/** * Checks whether the circular queue is empty or not. */ publicbooleanisEmpty() { return size == 0; }
/** * Checks whether the circular queue is full or not. */ publicbooleanisFull() { return size == arr.length; }
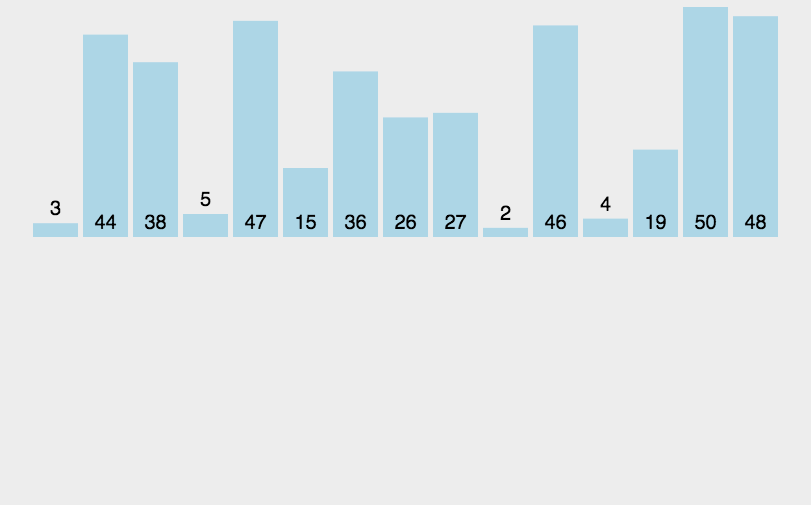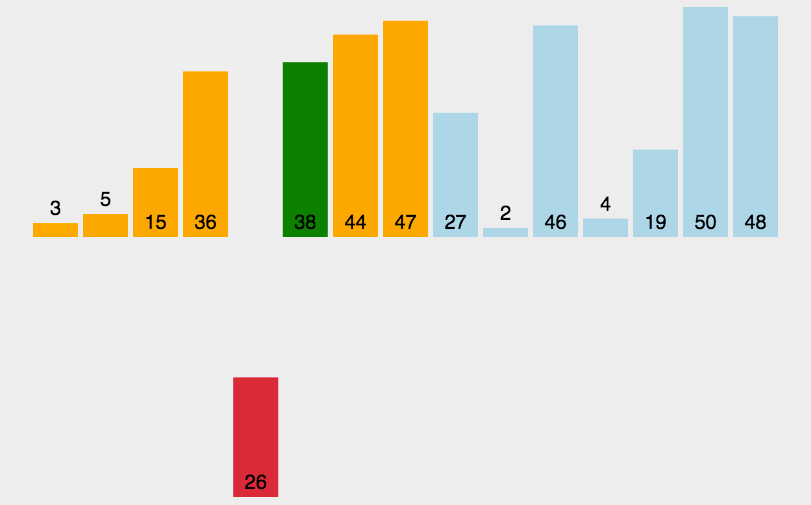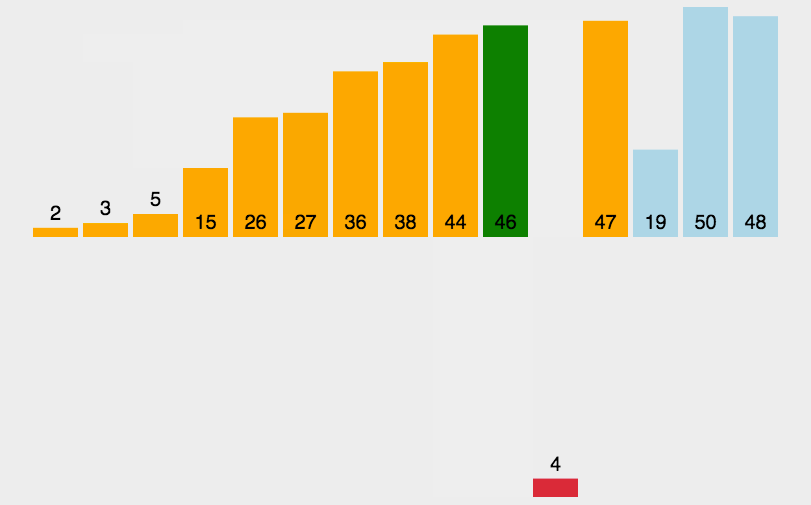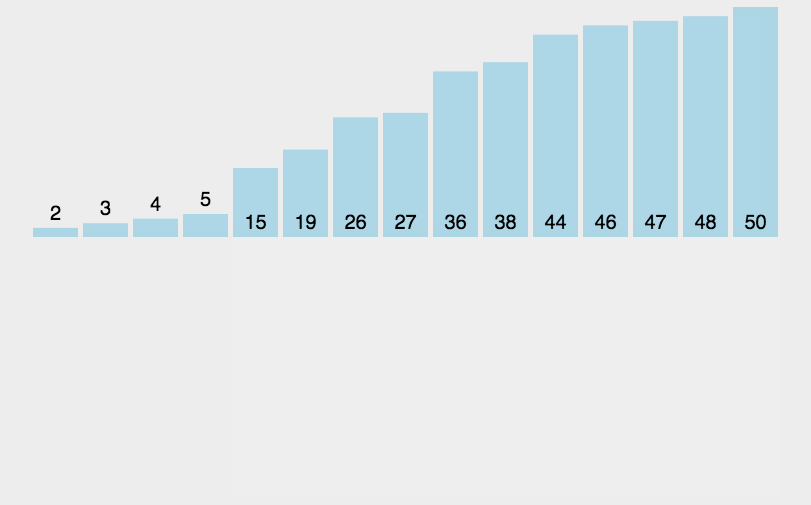
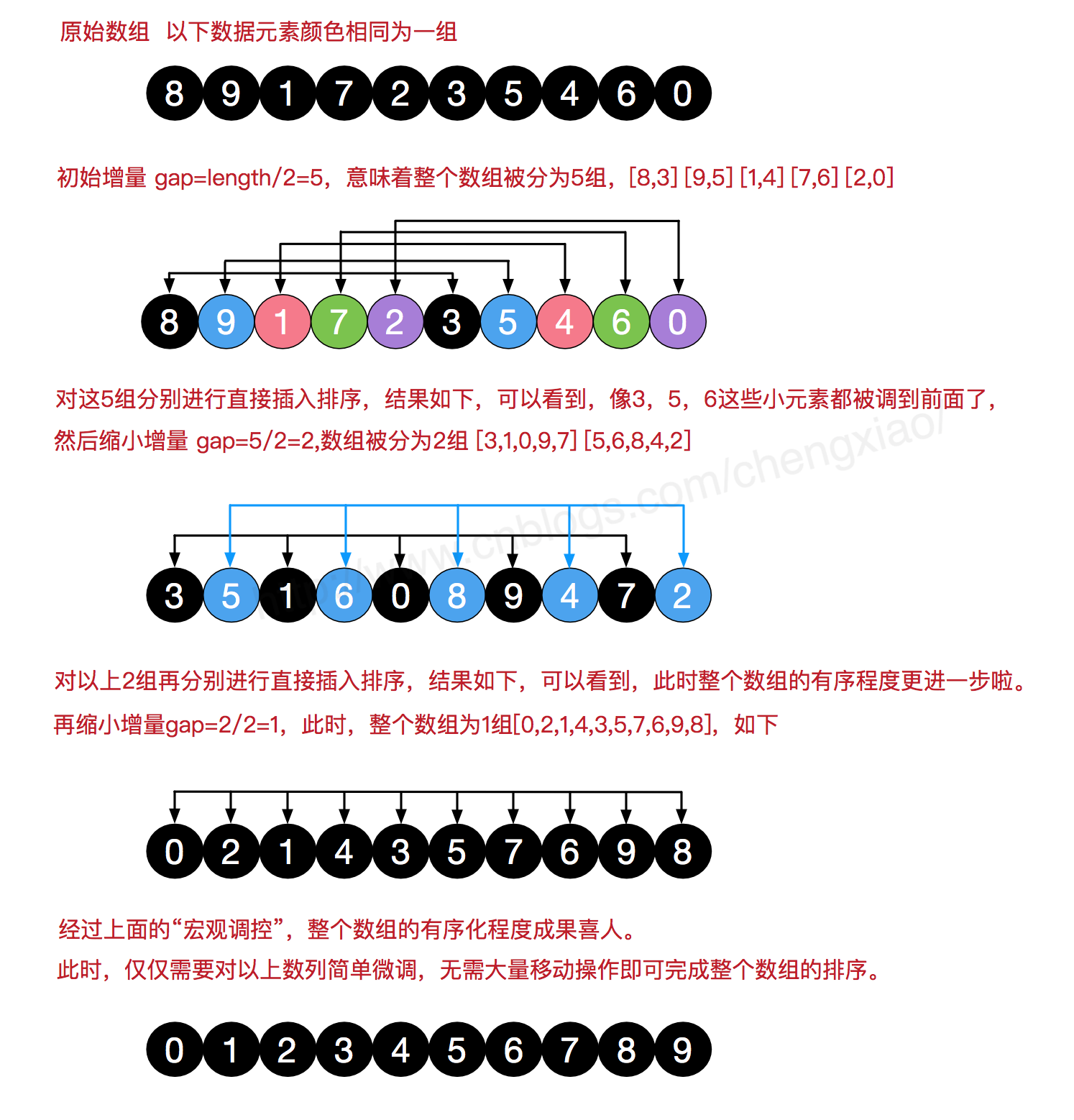
defshell_sort(arr): length = len(arr) gap = int(length / 2)
while gap > 0: for i inrange(gap, length): for j inrange(i, -1, -gap): # 相当于将插入排序的遍历的间隔由 1 改为 -gap, 即完成了分组 if arr[j] < arr[j - gap] and j - gap >= 0: arr[j], arr[j - gap] = arr[j - gap], arr[j] gap = int(gap / 2)
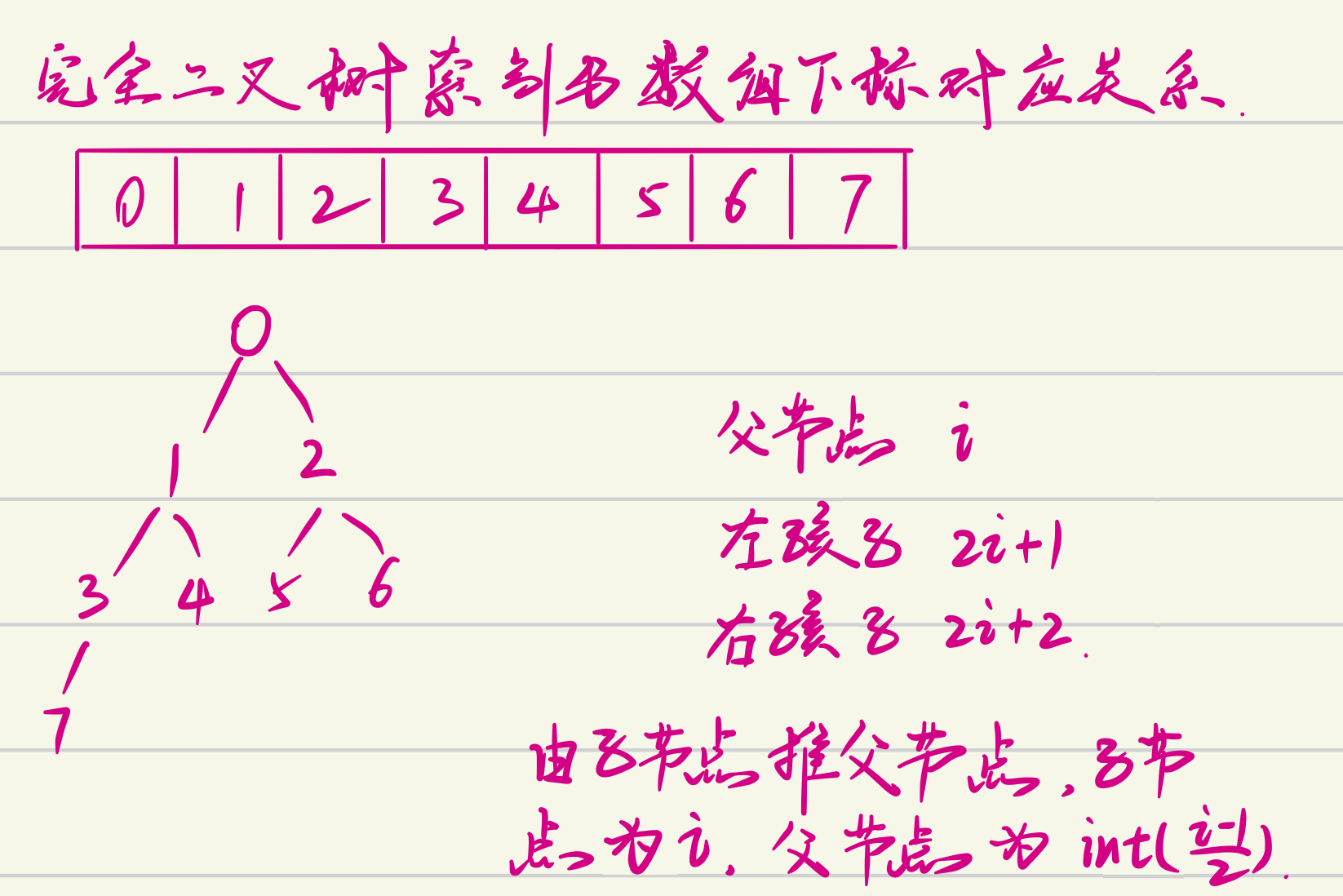
# 由堆的根节点开始向下调整,与其大孩子交换,逐层向下,使重新成堆 while left < heap_size: # 求出左右子中较大的一个 largest = left + 1if left + 1 < heap_size and arr[left + 1] > arr[left] else left # 求孩子与父节点中较大的一个 largest = largest if arr[largest] > arr[index] else index
if largest == index: break
arr[index], arr[largest] = arr[largest], arr[index] index = largest left = 2 * index + 1
# 改进实现, 双侧移动, 取最左侧为中轴元素 defpartition(arr: list, l: int, r: int) -> int: """ r(在右侧找到比中轴小的元素) => l(中轴) l(在左侧找到比中轴大的元素) => r(在右侧找到比中轴小的元素) 中轴值 => l/r(此时 l == r, 即 l 和 r 均指向左右部分的交界) """ p = arr[l] while l != r: while l < r and arr[r] >= p: r -= 1 arr[l] = arr[r] # 在右侧找到比中轴小的元素
while l < r and arr[l] <= p: l += 1 arr[r] = arr[l] # 在左侧找到比中轴大的元素
arr[l] = p # 此时 L = R, 即把中轴值赋给左右部分的交界位置 return l # 返回中轴索引
defquick_sort(arr: list, l: int, r: int) -> list: if l < r: p_index = partition(arr, l, r)
for i inrange(max_length): bucket_dict = dict() for ele in arr: digit = get_digit(ele, i) if bucket_dict.get(digit): bucket_dict[digit].append(ele) else: bucket_dict[digit] = [ele]
index = 0 for j inrange(10): if bucket_dict.get(j): for ele in bucket_dict[j]: arr[index] = ele index += 1
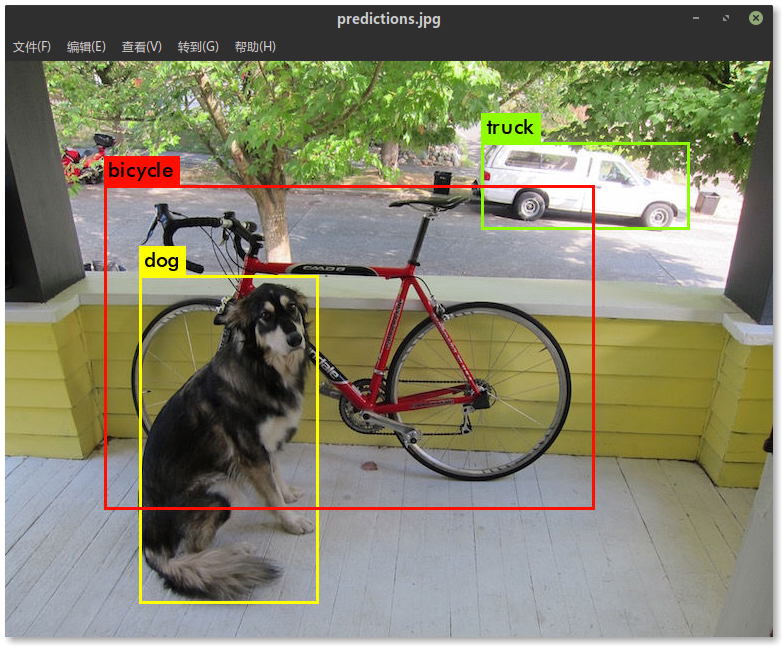
layer filters size input output 0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs 1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs ....... 105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs 106 detection truth_thresh: Using default '1.000000' Loading weights from yolov3.weights...Done! data/dog.jpg: Predicted in 0.029329 seconds. dog: 99% truck: 93% bicycle: 99%
cd .. python reval_voc.py --voc_dir NWPU_VHR-10_dataset/VOCdevkit --year 2007 --image_set test --class ./0913_NWPU_v3/NWPU.names ./valid_results
输出如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
Evaluating detections VOC07 metric? Yes AP for aeroplane = 0.9949 AP for ship = 0.8182 AP for storage_tank = 0.8013 AP for baseball_diamond = 0.9827 AP for tennis_court = 0.8040 AP for basketball_court = 0.8182 AP for ground_track_field = 0.9947 AP for harbor = 0.7442 AP for bridge = 0.8961 AP for vehicle = 0.8689 Mean AP = 0.8723
-------------------------------------------------------------- Results computed with the **unofficial** Python eval code. Results should be very close to the official MATLAB eval code. -- Thanks, The Management --------------------------------------------------------------