给定一个字符串 s 和一些长度相同的单词 words 。找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置。
注意子串要与 words 中的单词完全匹配,中间不能有其他字符,但不需要考虑 words 中单词串联的顺序。
示例 1:
输入: 输出: [0,9]
示例 2:
输入: 输出: []
题解 暴力解法 参考题解
创建两个 Map ,存储每个单词与单词出现次数的对应关系,wordMap 中保存输入数组 words 的词频信息;curMap 中保存逐位遍历输入字符串 s 的过程中产生的 wordMap 中含有的单词的词频。整体流程如下:
创建 wordMap ,保存输入数组 words 中单词和对应的词频
逐位遍历输入字符串 s ,记起始位为 start ,单词长度为 wordLen ,判断每次迭代 s[start, start + wordLen] 位置的单词是否在 wordMap 中
若不存在,跳出当前循环
若存在,则判断该词在 curMap 中出现次数是否超过其在 wordMap 中的词频
若超过,则跳出当前循环
若不超过,则增加 curMap 中该词的词频
若从某位置 i 开始,遍历过程中所有的词都符合条件,则将 i 放入结果集中。
时间复杂度:假设 s 的长度是 n ,words 里有 m 个单词,那么时间复杂度为 O(n * m) 。
空间复杂度:两个 HashMap,假设 words 里有 m 个单词,就是 O(m) 。
Java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import java.util.*;class Solution { public List<Integer> findSubstring (String s, String[] words) { List<Integer> results = new ArrayList <>(); int strLen = s.length(); int arrLen = words.length; if (strLen == 0 || arrLen == 0 ) return results; int wordLen = words[0 ].length(); HashMap<String, Integer> wordMap = new HashMap <>(); for (String word : words) { int value = wordMap.getOrDefault(word, 0 ); wordMap.put(word, value + 1 ); } HashMap<String, Integer> curMap = new HashMap <>(); int count = 0 ; for (int i = 0 ; i < strLen - arrLen * wordLen + 1 ; i++) { while (count < arrLen) { String curWord = s.substring(i + count * wordLen, i + (count + 1 ) * wordLen); if (wordMap.containsKey(curWord)) { int value = curMap.getOrDefault(curWord, 0 ); if (value + 1 > wordMap.get(curWord)) break ; curMap.put(curWord, value + 1 ); } else { break ; } count++; } if (count == arrLen) results.add(i); curMap.clear(); count = 0 ; } return results; } }
Python 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution : def findSubstring (self, s: str , words: list ) -> list : results = [] s_len = len (s) arr_len = len (words) if s_len == 0 or arr_len == 0 : return results word_len = len (words[0 ]) word_map = {} for word in words: value = word_map.get(word) word_map[word] = value + 1 if value else 1 for i in range (s_len - word_len * arr_len + 1 ): cur_map = {} count = 0 while count < arr_len: cur_word = s[i + count * word_len: i + (count + 1 ) * word_len] if cur_word in word_map.keys(): value = cur_map.get(cur_word) if value and value + 1 > word_map.get(cur_word): break cur_map[cur_word] = value + 1 if value else 1 else : break count += 1 if count == arr_len: results.append(i) return results
Go 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 func findSubstring (s string , words []string ) int { var results []int sLen := len (s) arrLen := len (words) if sLen == 0 || arrLen == 0 { return results } wordLen := len (words[0 ]) wordMap := make (map [string ]int ) for _, key := range words { wordMap[key] = wordMap[key] + 1 } for i := 0 ; i < sLen - wordLen * arrLen + 1 ; i++ { curMap := make (map [string ]int ) count := 0 for count < arrLen { curWord := s[i + wordLen * count: i + wordLen * (count + 1 )] if wordMap[curWord] != 0 { curMap[curWord]++ if curMap[curWord] > wordMap[curWord] { break } } else { break } count++ } if count == arrLen { results = append (results, i) } } return results }
滑动窗口法 参考题解
使用滑动窗口来优化遍历过程,假定输入为字符串 s 和字符串数组 words 。取满足条件时的字符串长度为滑动窗口大小,即 windowSize = len(words) * len(words[0]) ,分别从 i=0,1,2 开始移动窗口,每次移动 len(words[0]) 的长度即可覆盖全部情况。跳过移动过程中的重复校验可降低时间复杂度,有以下三种重复情况:
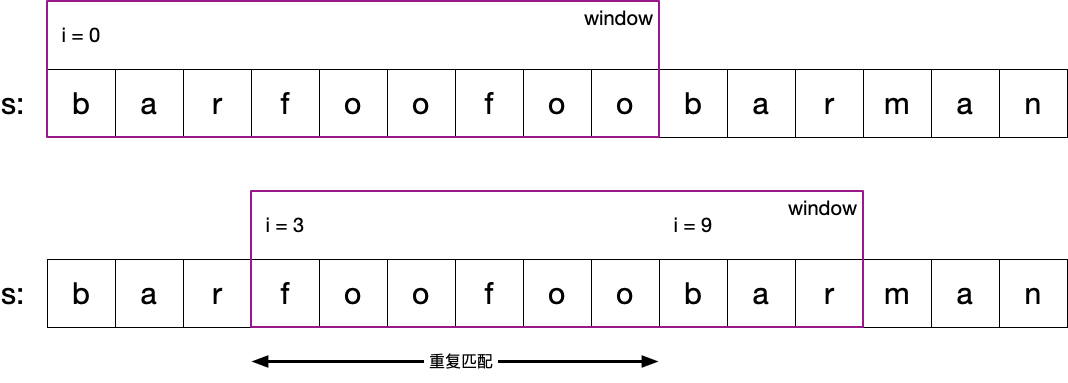
匹配成功,窗口后移出现重复匹配
1 2 s = 'barfoofoofoobarman' words = ['bar' , 'foo' , 'foo' ]
上图中 s[3:9] 已在 i=0 为开头的窗口中校验过,确认存在于 words 数组中,且词频未越界,故无需重复判断,直接校验 i=9 之后的字符即可。
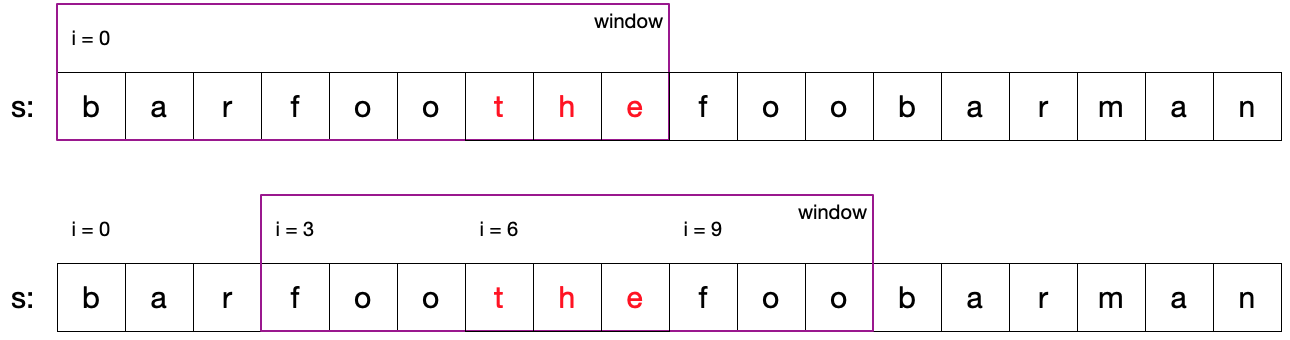
匹配失败,有 words 中不包含的单词
1 2 s = 'barfoofoothefoobarman' words = ['bar' , 'foo' , 'foo' ]
滑窗以 i=0 起始时,其中包含 words 数组中没有的 the ,匹配失败。而滑窗移动到 i=3 和 i=6 时又对 the 进行了重复校验,可直接将窗口移动到 i=9 位置跳过重复操作。
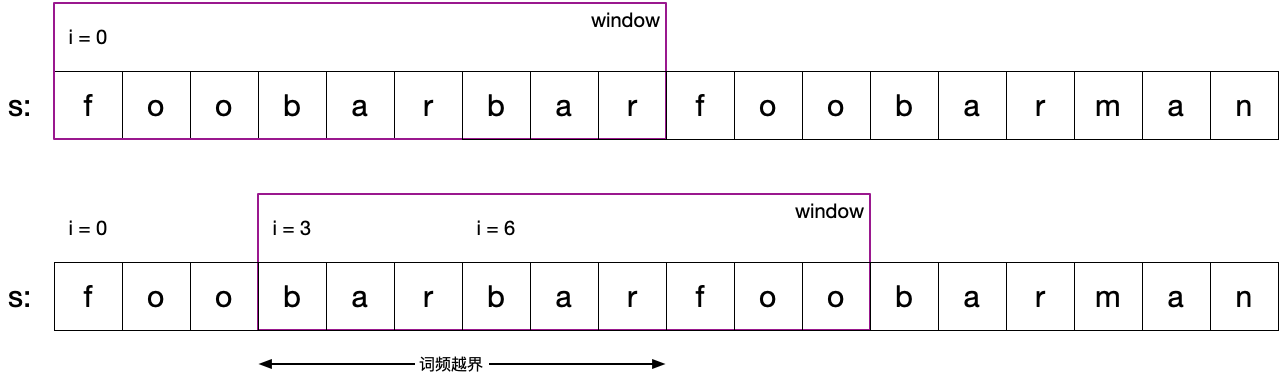
匹配失败,单词均在 words 中,但词频超出要求
1 2 s = 'foobarbarfoobarman' words = ['bar' , 'foo' , 'foo' ]
i=0 起始的窗口和 i=3 起始的窗口中均有两个 bar ,但 words 数组中仅有一个,可从 i=6 开始继续校验。
实际实现过程中,对窗口中的字符串进一步划分,每次只取 len(word[0]) 长度的子串,若该子串在 words 中且词频未越界,则增加该词在 curMap 中的词频。检验窗口中字符串的子串的过程中记录满足条件的单词数量 ,若当前窗口遍历完成后该数与 words 数组长度相等,则说明全部符合条件。
Java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import java.util.*;class Solution { public List<Integer> findSubstring (String s, String[] words) { List<Integer> results = new ArrayList <>(); int sLen = s.length(), arrLen = words.length; if (sLen == 0 || arrLen == 0 ) return results; int wordLen = words[0 ].length(); Map<String, Integer> wordMap = new HashMap <>(); for (String word : words) wordMap.put(word, wordMap.getOrDefault(word, 0 ) + 1 ); Map<String, Integer> curMap = new HashMap <>(); int windowSize = wordLen * arrLen; for (int i = 0 ; i < wordLen; i++) { int start = i; while (start + windowSize <= sLen) { String str = s.substring(start, start + windowSize); curMap.clear(); int j = arrLen; while (j > 0 ) { String curWord = str.substring((j - 1 ) * wordLen, j * wordLen); int count = curMap.getOrDefault(curWord, 0 ) + 1 ; if (count > wordMap.getOrDefault(curWord, 0 )) break ; curMap.put(curWord, count); j--; } if (j == 0 ) results.add(start); start += wordLen * Math.max(j, 1 ); } } return results; } }
Python 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution : def findSubstring (self, s: str , words: list ) -> list : results = [] s_len, arr_len = len (s), len (words) if s_len == 0 or arr_len == 0 : return results word_len = len (words[0 ]) word_map = {} for word in words: word_map[word] = word_map.get(word, 0 ) + 1 cur_map = {} window_size = word_len * arr_len for i in range (word_len): start = i while start + window_size <= s_len: cur_str = s[start: start + window_size] cur_map.clear() j = arr_len while j > 0 : word = cur_str[(j - 1 ) * word_len: j * word_len] count = cur_map.get(word, 0 ) + 1 if count > word_map.get(word, 0 ): break cur_map[word] = count j -= 1 if j == 0 : results.append(start) start += word_len * max (j, 1 ) return results
Go 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 func findSubstring (s string , words []string ) int { var results []int sLen, arrLen := len (s), len (words) if sLen == 0 || arrLen == 0 { return results } wordLen := len (words[0 ]) wordMap := make (map [string ]int ) for _, word := range words { wordMap[word]++ } windowSize := wordLen * arrLen; for i := 0 ; i < wordLen; i++ { start := i for start + windowSize <= sLen { curStr := s[start: start + windowSize] curMap := make (map [string ]int ) j := arrLen for j > 0 { curWord := curStr[(j-1 ) * wordLen: j * wordLen] count := curMap[curWord] + 1 if count > wordMap[curWord] { break } curMap[curWord] = count j-- } if j == 0 { results = append (results, start) } start += wordLen * max(j, 1 ) } } return results } func max (a, b int ) int { if a > b { return a } else { return b } }