二叉搜索树的最近公共祖先
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
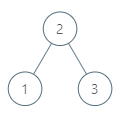
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]
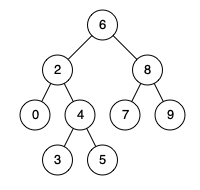
示例 1:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
输出: 6
解释: 节点 2 和节点 8 的最近公共祖先是 6。
示例 2:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4
输出: 2
解释: 节点 2 和节点 4 的最近公共祖先是 2, 因为根据定义最近公共祖先节点可以为节点本身。
说明:
- 所有节点的值都是唯一的。
p、q 为不同节点且均存在于给定的二叉搜索树中。
题解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| class Solution {
private TreeNode result;
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
lca(root, p, q);
return result;
}
private void lca(TreeNode root, TreeNode p, TreeNode q) {
if (((long) root.val - p.val) * (root.val - q.val) <= 0) result = root;
else if (root.val < p.val && root.val < q.val) lca(root.right, p, q);
else lca(root.left, p, q);
}
}
|
二叉树的最近公共祖先
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]
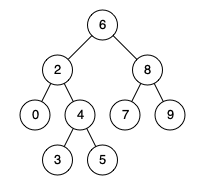
示例 1:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
输出: 6
解释: 节点 2 和节点 8 的最近公共祖先是 6。
示例 2:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4
输出: 2
解释: 节点 2 和节点 4 的最近公共祖先是 2, 因为根据定义最近公共祖先节点可以为节点本身。
说明:
- 所有节点的值都是唯一的。
p、q 为不同节点且均存在于给定的二叉搜索树中。
题解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| class Solution {
private TreeNode result;
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
lca(root, p, q);
return result;
}
private void lca(TreeNode root, TreeNode p, TreeNode q) {
if (((long) root.val - p.val) * (root.val - q.val) <= 0) result = root;
else if (root.val < p.val && root.val < q.val) lca(root.right, p, q);
else lca(root.left, p, q);
}
}
|
二叉树的最近公共祖先 II
给定一棵二叉树的根节点 root,返回给定节点 p 和 q 的最近公共祖先(LCA)节点。如果 p 或 q 之一 不存在 于该二叉树中,返回 null。树中的每个节点值都是互不相同的。
根据维基百科中对最近公共祖先节点的定义:“两个节点 p 和 q 在二叉树 T 中的最近公共祖先节点是 后代节点 中既包括 p 又包括 q 的最深节点(我们允许 一个节点为自身的一个后代节点 )”。一个节点 x 的 后代节点 是节点 x 到某一叶节点间的路径中的节点 y。
示例1:
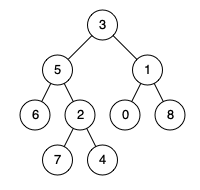
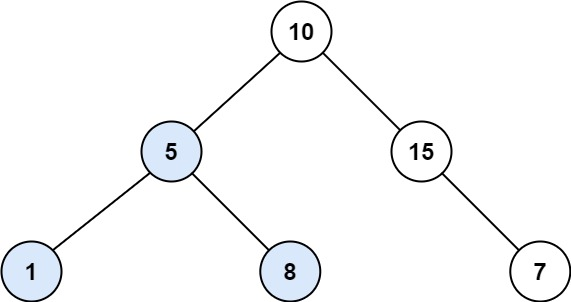
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出: 3
解释: 节点 5 和 1 的共同祖先节点是 3。
示例2:
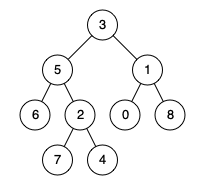
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。
示例3:
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 10
输出:null
解释:节点 10 不存在于树中,所以返回 null。
提示:
- 树中节点个数的范围是 [1, 104]
- -109 <=
Node.val <= 109
- 所有节点的值
Node.val 互不相同
p != q
题解
本题不保证 p 和 q 存在于树中,以下为本系列题的通用解,四个题目全都可以通过。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| class Solution {
private TreeNode result;
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
dfs(root, p, q);
return result;
}
private int dfs(TreeNode root, TreeNode p, TreeNode q) {
if (root == null) return 0;
int res1 = dfs(root.left, p, q);
int res2 = dfs(root.right, p, q);
int res3 = (root == p || root == q) ? 1 : 0;
int cnt = res1 + res2 + res3;
if (cnt == 2 && result == null) result = root;
return cnt;
}
}
|
二叉树的最近公共祖先 III
给定一棵二叉树中的两个节点 p 和 q,返回它们的最近公共祖先节点(LCA)。
每个节点都包含其父节点的引用(指针)。Node 的定义如下:
1
2
3
4
5
6
| class Node {
public int val;
public Node left;
public Node right;
public Node parent;
}
|
根据维基百科中对最近公共祖先节点的定义:“两个节点 p 和 q 在二叉树 T 中的最近公共祖先节点是 后代节点 中既包括 p 又包括 q 的最深节点(我们允许 一个节点为自身的一个后代节点 )”。一个节点 x 的 后代节点 是节点 x 到某一叶节点间的路径中的节点 y。
示例1:
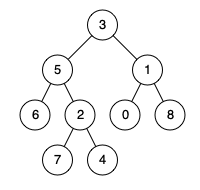
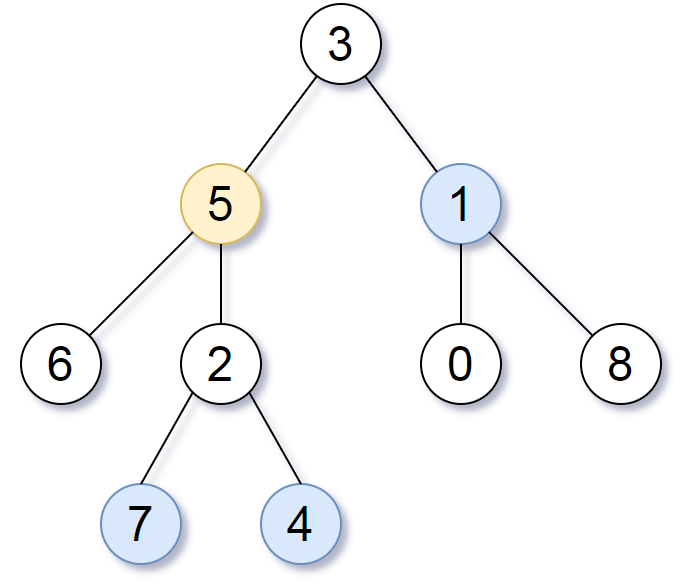
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出: 3
解释: 节点 5 和 1 的最近公共祖先是 3。
示例2:
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出: 5
解释: 节点 5 和 4 的最近公共祖先是 5,根据定义,一个节点可以是自身的最近公共祖先。
示例3:
输入: root = [1,2], p = 1, q = 2
输出: 1
提示:
- 树中节点个数的范围是 [2, 105]。
- -109 <=
Node.val <= 109
- 所有的
Node.val 都是互不相同的。
p != qp 和 q 存在于树中。
题解
由于本题加入了 parent,可采用类似求相交链表交点的方法求解。
1
2
3
4
5
6
7
8
9
10
11
12
| class Solution {
public Node lowestCommonAncestor(Node p, Node q) {
Node a = p, b = q;
while (a != b) {
a = a == null ? q : a.parent;
b = b == null ? p : b.parent;
}
return a;
}
}
|